2022年8月26日,由科大讯飞和中国科学技术大学联合承建的认知智能国家重点实验室在“面向金融领域的Few-Shot事件抽取”技术评测中,凭借融合实体抽取与文本分类的小样本事件抽取方案,取得该项评测的第一名。
[ 任务挑战 ]
“面向金融领域的Few-Shot事件抽取” 是中国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,以下简称CCKS)推出的技术评测类任务,旨在考察在提供部分事件标注样本的情况下,机器对未标注或者欠标注事件进行主体抽取的能力。
小样本学习在机器学习领域具有重大挑战,其要求通过极少量样本的学习,让机器建立起对新事物的认知,并具备泛化能力。就本项评测而言,评测任务具备两大难点:
1.存在多种数据噪声
原始文本语料来自于互联上的公开新闻、报告,存在多种噪声,在Few-Shot事件样本不多的情况下,再次增加了模型对文本语义理解和事件学习的难度。
2.类别极不均衡
事件类别极不均衡且训练集和测试集分布不同。训练集共有近6万条样本,包含173个事件类别。但其中的16个Few-Shot事件类型在训练集中标注样本数量极少,每类仅有10条左右的训练样本,但该16类事件在测试集中却占比很高,且评测时对Few-Shot事件类型将给予更高的权重,这对模型的鲁棒性和精确性都提出了更高的要求,也极大增加了比赛难度。
[ 方案设计 ]
实验室凭借多年技术积累与不断探索创新,在分析了数据特点并调研相关研究后,设计了一套融合实体抽取与文本分类的小样本事件抽取方案,整体方案由数据预处理及增强、实体识别(事件主体抽取)、事件分类三个子模块组成。
方案创新性地将事件抽取任务转化为事件主体识别及事件分类两项子任务。其一,统一的事件主体识别模型克服了样本不均衡带来的预测偏差等问题。其二,在事件分类模型中通过两段式的训练方法,充分挖掘了Few-Shot事件类型的语义特征,使得模型在极少量样本的情况下也能具备出色的事件抽取能力。
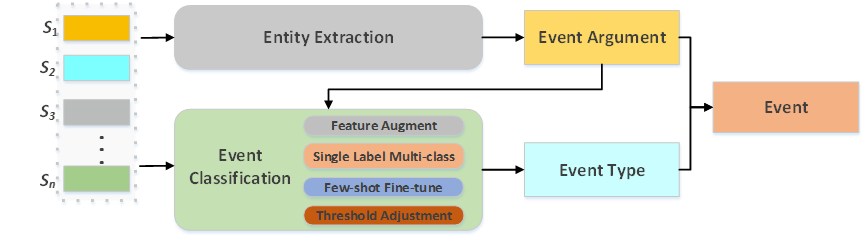 系统设计方案
系统设计方案
1.更有效的Few-Shot数据增强
在数据预处理与增强模块中,实验室结合Few-Shot事件特征,设计了一套高效的数据增强方案,有效扩充了Few-Shot事件样本,缓解了数据分布不均衡问题,强化了模型对Few-Shot事件类型的样本学习。
2.更精准的Few-Shot特征提取
为了强化模型对Few-Shot事件类型的理解,实验室设计了融合多种语义特征的事件分类模型。该模型基于对极少量样本的学习,即可拥有优秀的语义表征能力。
3.更鲁棒的Few-Shot事件表征
实验室设计了一套两段式的模型训练方法,在采用全量数据训练的基础模型收敛之后,再次使用Few-Shot事件类型的数据进行模型微调,通过控制超参数,让模型再次学习Few-Shot事件特征,使得模型具备更加鲁棒的Few-Shot事件编码能力,极大提升了模型性能。
4.更灵活的阈值调整策略
通过在推理阶段使用调整阈值的策略,实现了针对小样本的多标签输出,使得单标签多分类模型更加灵活,能更好应对非平衡数据,在保证Few-Shot事件精准率的前提下,提升了召回率。
[ 技术探索与应用 ]
本次事件抽取评测中,实验室设计的融合实体抽取与文本分类的小样本事件抽取方案,克服了数据噪声和事件类别不均衡难题,为后续多种场景下事理图谱的构建和应用奠定基础。
实验室将持续探索小样本下的事件抽取方案,并在数字政府、城市超脑、智慧园区、智慧水利等诸多业务场景中进行事理图谱构建、智能搜索、智能推荐等应用落地及推广。此外,实验室将以事件抽取为核心,面向智慧司法行业场景开展司法证据链分析审查等应用实践,辅助办案人员实现案情内容抽取、关联、矛盾检测的提质增效,支持我国司法系统智能化水平全面提升;同时面向教育、医疗等关乎国计民生的行业场景,不断夯实认知智能共性基础技术,服务国家科技战略,为实现机器“能理解会思考”的使命贡献自己的一份力量。
来源:长三角信息智能创新研究院 编辑:唐菁莲 校对:罗添 预审:施羽晗 终审:聂竹明