在2022年智能与语言技术竞赛——段落检索赛道榜单中,由科大讯飞和中国科学技术大学联合承建的认知智能国家重点实验室凭借基于弱监督数据预训练的开放问答段落检索系统登顶,使得大规模语义段落检索技术离“更精准、更全面”更近一步。
智能与语言技术竞赛由中国中文信息学会、中国计算机学会联合主办,覆盖自然语言处理和人工智能领域的重要前沿课题。其中段落检索赛道旨在让机器从大规模语料库中找出和用户查询最相关的段落,评估机器的语义理解及检索的能力。该比赛评估指标包括平均倒排MRR@10、Top-1段落召回以及Top-50段落召回,实验室在MRR@10、Top-1段落召回中均取得最佳成绩,最终以MRR@10指标0.8574的成绩获得冠军。

智能与语言技术竞赛段落检索赛道官方榜单
[ 什么是段落检索? ]
段落检索,顾名思义就是从大量段落中检索与问题相关的段落。日常生活中,我们常常会去检索一些常识问题或热点问题的相关段落或者文档。
如何从一个百万级甚至千万级的大型文档库中准确并有效检索出与问题最相关的段落,以满足人类的需求,这一直是信息检索的难点。段落检索作为许多自然语言处理任务中的关键组件,是自然语言处理和人工智能领域的重要前沿课题,近年来受到了学术界和工业界的广泛关注。
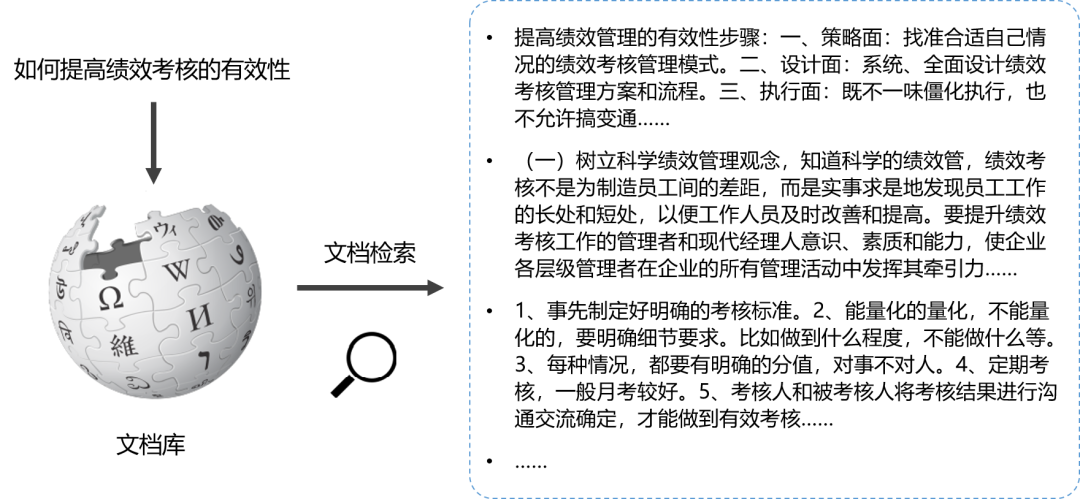
文档检索系统
[ 如何做段落检索?]
段落检索最简单的方法就是通过文字匹配找出与问题最相似的段落,然而该类方法很难有效处理一些复杂自然语言问题。近年来,业界和学术界均在探索基于深度学习模型的复杂自然语言问题语义表示方法,以及面向篇章和复杂句子的语义相似度计算方法。
当前段落检索主流方案是使用语言模型对问题和段落分别编码,随后计算问题向量和段落向量的相似度进行粗排,最后将粗排召回的段落和问题拼接使用交叉编码模型精排获得最终检索结果。这种通过粗排再精排的两步检索方案相比于直接使用文本相似度匹配有很大提升。
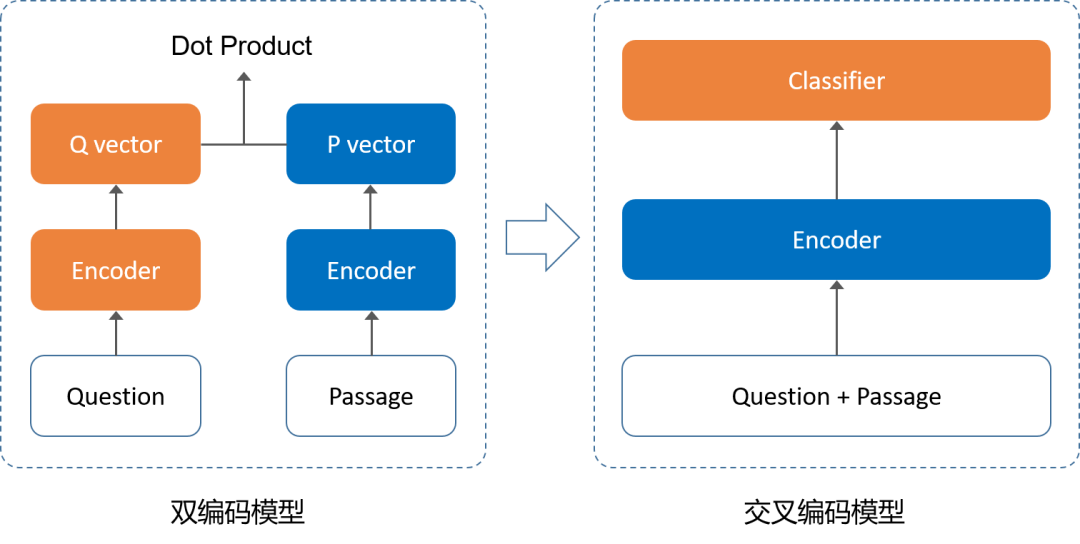
大规模段落检索“粗排—精排”系统
[ 段落检索的难点 ]
首先,目前没有大规模段落检索人工标注数据集。人工标注数据集需要标注出问题和问题所在文档库中的一系列正确段落,标注过程往往费时费力。
另一个难点在于如何寻找困难负样本。为了训练深度学习模型,需要构建不能回答问题的负样本段落。如果负样本段落与正确答案的段落有很多相似之处,我们将其称之为困难负样本。随机筛选的负样本通常过于简单,模型难以获得很好的训练。如果加入一些困难负样本,可以极大提升模型训练的鲁棒性。然而,困难负样本中往往存在一些没有标注出来的伪负例,如何排除伪负例是引入困难负样本的重中之重。
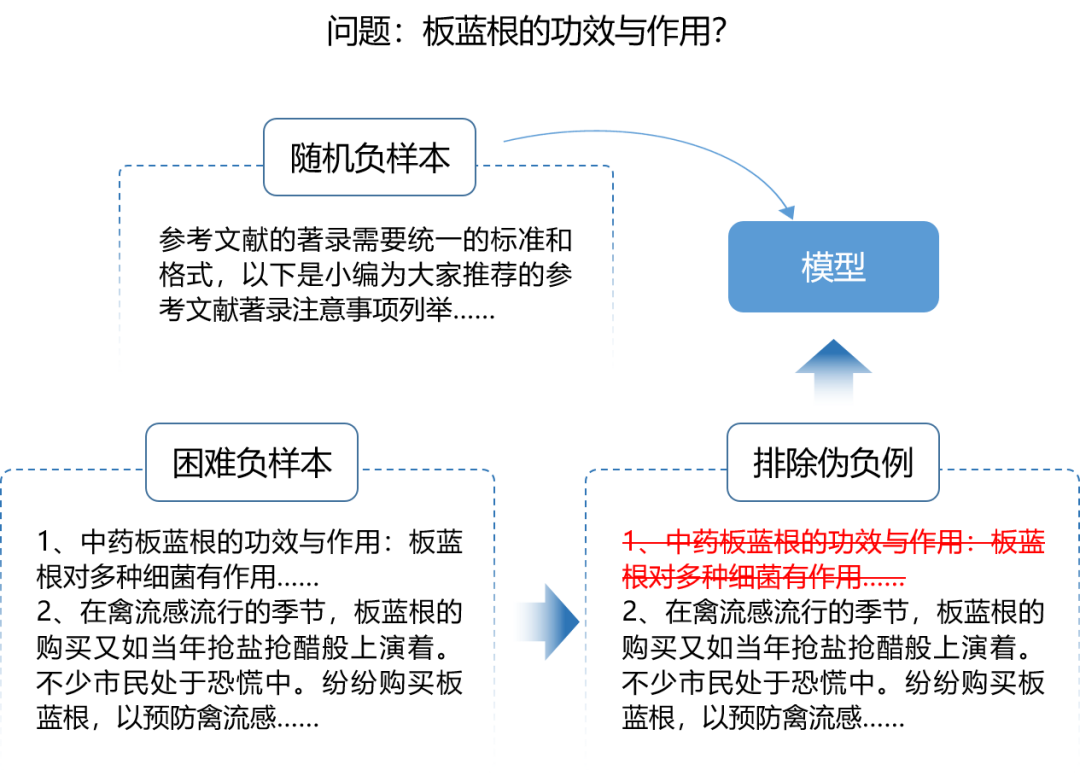
段落检索模型负样本构造示例
[如何更准确地进行段落检索?]
实验室通过多年的技术积累及不断探究,提出了一套基于弱监督数据预训练的开放问答段落检索方案,有效解决人工标注训练样本不足以及困难负样本筛选问题。该方案创新点如下:
基于以上两种方法并结合多项技术打造的检索系统最终在测试集上的MRR@10达到0.8574,Top-1召回率达到0.7937。
[ 技术应用落地 ]
在开放域问答领域,机器所需解决的一大问题就是在大量不同主题文档中,查找与用户问题相关的文档,并根据该文档内容回答问题。有效的段落检索系统可以极大提升开放域问答的准确性。
目前,实验室已经在多个业务场景中实现了开放域问答的落地。通过构建大规模篇章库,机器可以回答日常百科、热点信息等问题,甚至可以处理医学、汽车等领域中更加专业的问题,为用户提供更精准有效的智能信息服务。
未来,实验室将继续面向真实应用需求,持续开展问答系统在多个领域的研究,并探索在更多场景中的落地应用,用人工智能建设美好世界。
来源:长三角信息智能创新研究院 编辑:唐菁莲 校对:罗添 预审:施羽晗 终审:聂竹明