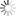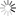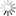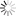这是出现在QASC常识推理挑战赛的一道题目,你做对了吗?
近日,认知智能国家重点实验室与哈工大联合团队夺得常识推理挑战赛QASC榜首,以多模型准确率93.48%、单模型准确率92.07%的成绩均创造榜单最好成绩,超越了第二名谷歌团队90.65%的纪录。这也是实验室继OpenBookQA夺冠之后,在常识推理任务上再次超越人类平均水平。
聚力常识推理技术攻坚 夺冠佳绩领先世界
在人工智能技术从感知智能迈向认知智能的攻坚阶段,常识推理是重要一环。
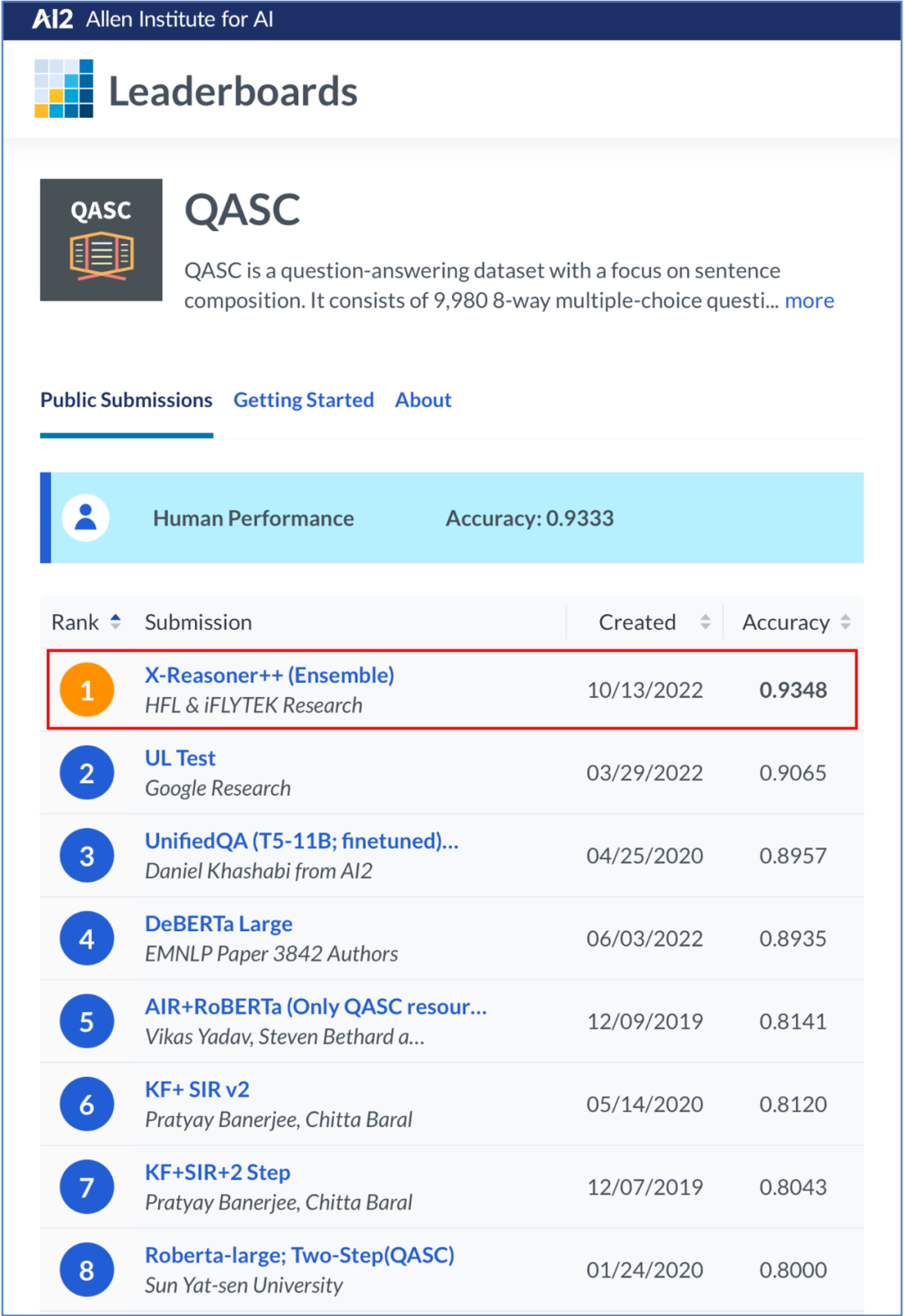
认知智能国家重点实验室与哈工大联合团队登上榜首
求索未止,领先技术再迎创新。本次夺得QASC榜首,是由团队对前述OpenBookQA比赛中夺冠系统X-Reasoner改造升级,推出X-Reasoner++,实现知识检索和运用能力全面提升的结果。
夺冠系统再升级 以“双保险”应对大赛新挑战
QASC(Question Answering via Sentence Composition)是由艾伦人工智能研究所(AI2)推出的常识推理阅读理解任务,旨在评估机器对常识的理解和应用能力。该挑战赛吸引了谷歌、亚利桑那大学、中山大学等研究机构和知名高校的参与。
以文章开头的题目为例,从问题推理到答案,要利用到以下两条知识:
(1)抗体是用来对抗抗原的;(2)引起过敏的抗原被称为过敏原。

QASC任务中的问题示例
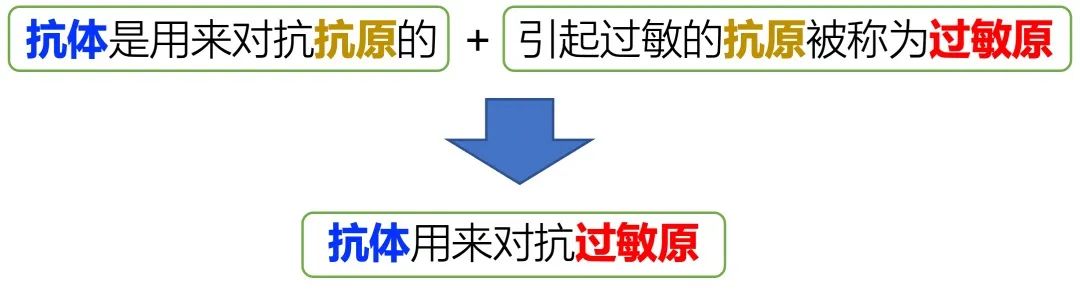
常识结合生成与问题相关的知识
因此,对于常识问答系统来说,首先,它要能从千万量级的海量的知识库中准确检索到相关的知识;同时,模型要能正确地将两条知识进行结合,建立两条常识之间的关系,才能与问题相匹配,最终得到正确选项。由此可见,想要提高回答准确率,出色的常识检索、常识运用的能力是必不可少的条件。像这样的题目,在QASC比赛中机器需要做920道,系统所答对的题目数量所占比例,即是挑战赛所关注的成绩,也是夺冠的关键。
面对QASC任务中提出的新挑战,团队对OpenBookQA上的夺冠系统X-Reasoner改造升级,推出X-Reasoner++,利用“双保险”全面提升机器阅读理解系统对知识的检索和运用能力:
(1)多步知识检索策略。有时题目所涉及的常识并不都与问题的字面信息直接相关,系统会先检索并挑选与题相关的高置信度知识,再检索与这些高置信度知识相关的额外知识。最终将题目和所有检索到的相关知识一起送入机器阅读理解模型。多步知识检索策略的流程如下图所示。
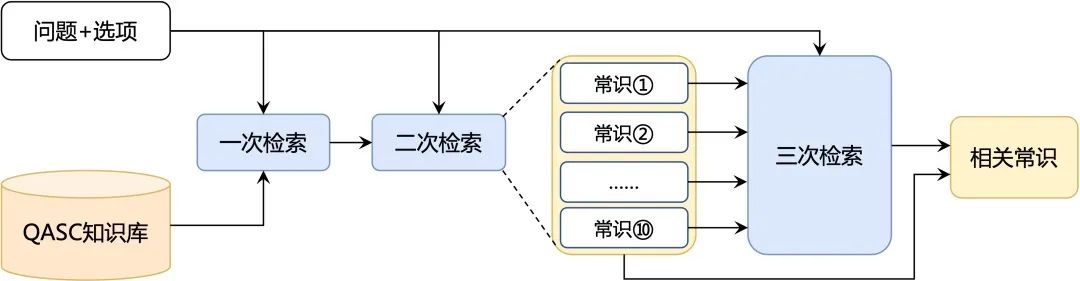
多步知识检索策略流程
(2)预训练常识注入。作为另一道保险,本系统中使用了知识库对模型进行预训练,将常识知识显式地注入到预训练模型,提升模型对常识知识的运用能力。即便多步知识检索中有所遗漏,模型也可凭借其自身内部蕴含的知识储备理解和回答问题,减少了因知识检索缺失导致回答错误的情况。
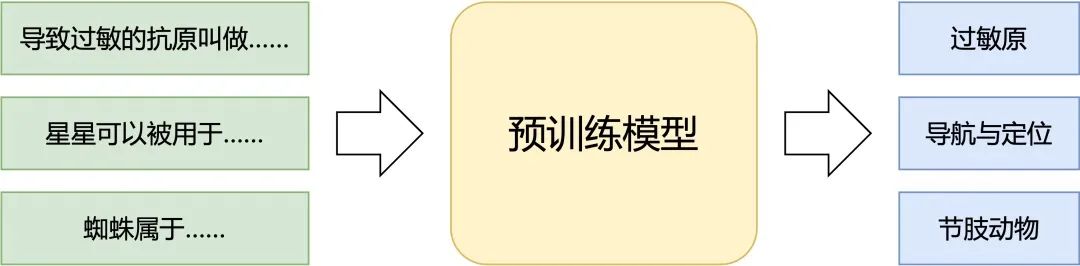
预训练常识注入
通过以上创新点的结合,X-Reasoner++单模型相比榜单之前最好系统在准确率上提升1.4%,并且X-Reasoner++多模型效果进一步提升至93.48%,也就是说,在应对比赛中共920道题目时,系统答对了860道,而官方公布的人类所能达到的平均准确率是93.33%,实现全球首次超越人类平均水平!
近年来,实验室在常识推理领域集中发力,取得了一系列成果。今年4月,在CommonsenseQA 2.0常识推理挑战赛中,提出融合知识的深度神经网络ACROSS模型,以76.06%的成绩获得第一;7月,登上OpenBookQA科学知识推理挑战赛榜首,创新性提出X-Reasoner模型,以准确率94.2%的绝对优势夺冠,实现常识推理单模型全球首超人类平均水平。
此外,实验室的技术成果也不断被应用在各类科技产品中,赋能千行百业。例如在医疗领域,2017年智医助理就已在国家临床执业医师考试笔试中获得456分,超过96.3%的考生,今年三季度,已在全国380个区县实现常态化应用,规范电子病历1.83亿次,识别不合理处方3711万次,高价值修正诊断超59.1万次。未来,实验室将在认知智能领域进一步深耕,坚持源头核心技术创新,让更多的人工智能产品服务于教育、医疗、养老等国计民生场景,用人工智能建设美好世界。
来源:长三角信息智能创新研究院 编辑:唐菁莲 校对:罗添 预审:施羽晗 终审:聂竹明