2022年8月26日,由科大讯飞和中国科学技术大学联合承建的认知智能国家重点实验室荣获开放知识图谱问答评测冠军,创新性地提出了知识图谱深度语义推理模型,以显著优势夺得冠军,相较第二名准确率得分高出约4%。
开放知识图谱问答评测是中国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,以下简称CCKS)推出的技术评测类任务,该评测任务旨在考察问答系统在知识图谱中找到答案的能力。
问答系统不仅要理解用户多样的提问表达方式,还要在6000多万三元组知识构成的知识图谱中通过推理找到正确答案。任务知识图谱中不仅包含通用领域的知识(如历史、名著、名人等),同时也涵盖垂直行业领域知识(如医疗、金融、旅游、城市服务等),使得此项任务极具挑战。
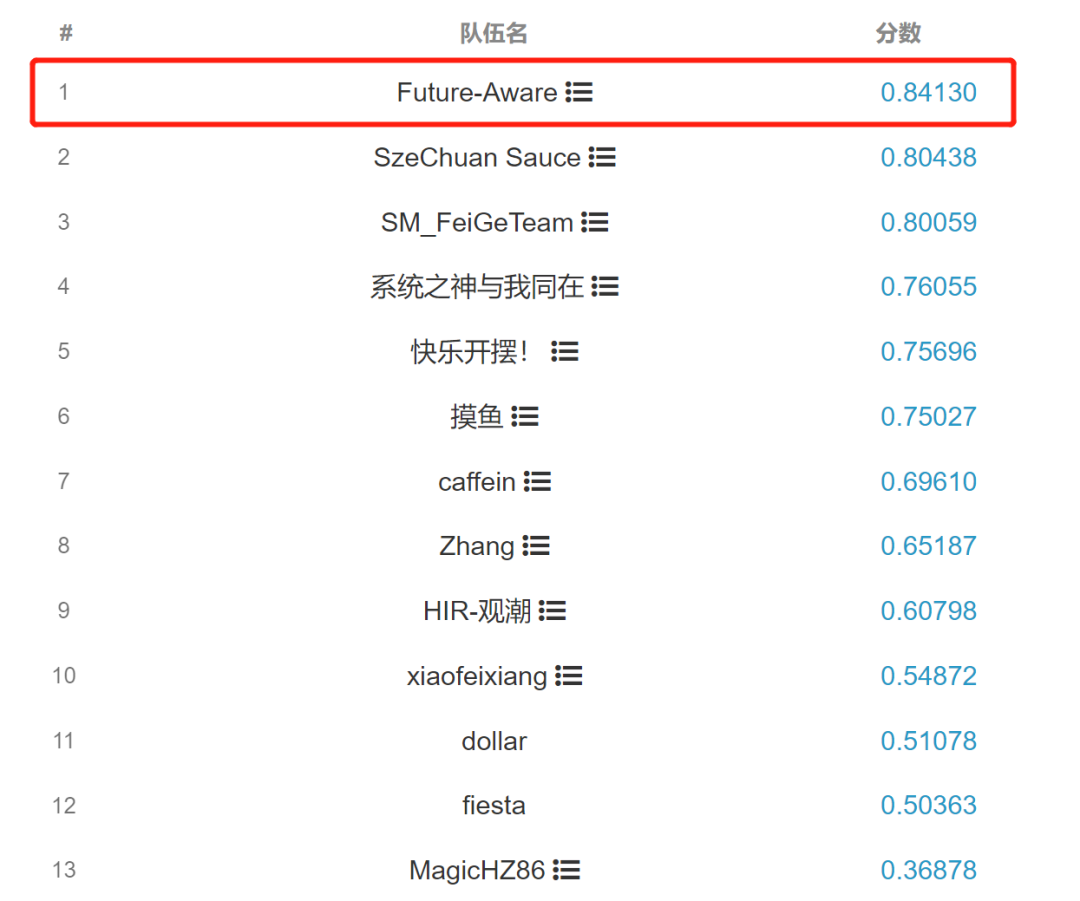 最终得分 – CCKS2022:开放知识图谱问答
最终得分 – CCKS2022:开放知识图谱问答
[ 任务挑战 ]
1、如何像人类大脑一样理解和推理
如:九寨沟附近5公里内价格低于500的哪个酒店能唱歌?
提问句中,需要像人脑一样理解在20多个字的一句话中“九寨沟”“5公里内”“价格低于500元”“提供KTV服务的酒店”这么多重要条件信息并理解这些信息间逻辑关系。信息量级和语义难度已经不是传统逻辑推理和问答系统能够处理的范畴。此外,在图谱中含有“九寨沟”“九寨沟县”“九寨沟风景区”等多个相似实体,如何按照人的大脑一样去思考匹配到最佳实体“九寨沟风景区”是一个艰巨的挑战。
2、如何在海量信息中快速得到需要的答案
该任务的难点在于,机器需要在6000多万三元组超大规模的图谱中进行检索,常用的图谱检索方法难以奏效,同时需要应对由多样的问题描述方式所带来的路径匹配困难的问题。传统方法通常会采用语义匹配的方式,但若应用在和本次比赛差不多的海量规模知识图谱上,这会导致资源消耗过大,且信息检索速度非常缓慢,像是在对一个睡着的人提问一样,“很久没有答案”。
[ 方案设计 ]
1、更精准的语义理解
“听清楚对方在讲什么”,在作出解答前,模型首先需要捕捉问题中的关键信息,以便针对问题进行精准理解和推理。本模型采用基于多头标注矩阵和阅读理解的注意力交互机制,同时使用标签平滑损失来进一步解决关键信息分布不均衡问题,对原始问题中实体提及的重要程度进行综合打分。
2、更全面的实体链接
“咱俩说的是同一个东西吗?我懂你意思”,中文博大精深,即使对同一事物的描述,也是说法不一,在抓住问题重点的同时,还需要转化为机器能够理解的语言。本模型提出一种融合检索与生成的实体链接方案。使得模型能够“读懂”问题中隐性语义,预测出知识图谱中的相关实体,与上述指标一起送入实体链接模块进行计算。
3、基于自监督学习的知识推理
“这个解题思路看起来更合理一些”,模型依照人类思考的逻辑,模拟人脑在知识图谱中多跳推理的过程。在筛选候选路径方面,本模型采用集束搜索策略,综合挑选出当前状态下最合理的5条路径进入下一轮推理。在路径打分方面,本模型基于自监督对比学习架构,使得模型能够参考正确路径和错误路径同时进行学习,以此获得精准感知路径变化的能力。
[ 技术探索与应用 ]
近年来,围绕国家在教育、医疗、人机交互、跨语种交流等领域的需求,认知智能国家重点实验室积极开展认知智能核心技术攻关和落地应用,研发的具备行业专业知识的复杂认知智能系统已在智慧教育、智慧医疗、智慧城市等诸多场景得到应用,缓解优质行业专家资源不足等问题。
例如,科大讯飞在智慧城市领域打造了基于AI+知识图谱+大数据模型的知识中台,知识中台基于人工智能技术构建全链路知识管理能力,覆盖了知识的高效生产、灵活组织和智慧应用,是面向城市知识生产、管理和应用的全生命周期一站式智能化知识解决方案。截至目前,知识中台已经在数字政府、城市超脑、智慧园区、智慧水利、智慧司法等行业落地应用。
为进一步提升机器的认知智能水平,实验室明确将知识学习及推理作为迈向认知智能2.0的四大任务之一。未来,实验室将持续探索深度语义理解、多源异构知识融入等认知智能共性技术基底技术,搭建大规模、多领域的知识图谱自动构建系统,致力于让机器逐步具备综合运用人类语言和知识的认知智能能力,并在教育、医疗、养老等国计民生场景中发挥更大的价值。
来源:长三角信息智能创新研究院 编辑:罗添 校对:唐菁莲 初审:施羽晗 终审:聂竹明