摘 要:以深度神经网络为代表的新一代人工智能技术,为推动教育数字化转型与智能化升级提供了底层支撑,智能教育成为当前全球教育发展的显著特征与重要趋势。但由于神经网络普遍存在的黑箱属性,难以阐释模型的决策过程或显性表达模型的内部知识,导致在教育实践中往往“知其然而不知其所以然”,制约了智能教育的纵深发展。为应对这一挑战,需从以下方面着力:揭示推动教育从可计算到可解释计算跃迁的多维因素,建立覆盖智能建模核心流程的教育可解释计算逻辑框架,发展具有因果效应的教育可解释计算技术路向。此外,教育可解释计算的长远发展还依赖于理论引导、评测适配与个性关切。
关键词:智能教育;可解释计算;逻辑框架;技术路向;
以深度神经网络为代表的新一代人工智能技术在各领域得到广泛应用,但各种负面问题也逐渐显现,特别在关乎个人福祉和公共利益的场景,端到端的神经网络算法普遍存在的黑箱属性,容易引发智能系统安全隐患,导致人们对机器的不信任,如何提升机器决策的可解释性成为热点。我国在《新一代人工智能发展规划》中明确提出“实现具备高可解释性、强泛化能力的人工智能”。美国国防高级研究局启动了可解释人工智能专项研究计划,旨在全面开展可解释人工智能研究[1]。对智能教育而言,如何利用神经网络强大的数据拟合与建模能力,研发更精准的算法模型,发展更智能的应用服务,应对学习场景开放、主体状态内隐、服务模式多元等难题,成为领域学者的普遍追求,有效促进了教育的数字化转型与智能化升级。但由于难以阐释神经网络模型的决策过程或显性表达模型的内部知识,教育实践往往面临“知其然而不知其所以然”的困境,无法为学生提供归因分析、错因追溯等具有更高教育价值的服务,制约了智能教育的纵深演进。因此,发展教育可解释计算,既是教育追求“知其然且知其所以然”的内在诉求,也是突破智能教育发展瓶颈的必然选择。
一、教育可解释计算的发展动因
作为一种普适性技术,人工智能对教育产生的影响是全方位的,贯穿理论研究、技术突破与应用创新多个层面。例如,以计算教育学为代表的数据密集型研究范式开启了教育研究新范式的讨论热潮,以深度神经网络为代表的“深度+”技术路线已成为推动智能教育关键技术突破的主要驱动力,以智能助教、智能学伴为代表的智能教育创新应用不断涌现。实际上,教育的可解释需求同样蕴含在智能教育发展的各个层面。
(一)范式转换: 计算教育学的应有之义
从研究层面,人工智能赋能教育的一大特征是开启了数据密集型教育研究范式,诞生了教育学新思潮与人工智能新技术应时融合而生的“计算教育学”新方向。计算教育学以教育大数据为研究对象,通过技术赋能,围绕教育主体计算、情境计算、服务计算等核心任务开展研究与实践[2],引发了诸多学者关于数据驱动、计算主义如何促进教育理论与实践创新的思考,并由此掀起了以量化分析、计算建模为核心要义的各类教育研究探索。但计算教育学终归属于教育学范畴,其研究范式除了具有数据化、计算化等典型特征,同样需继承基于解释学,注重对教育现象或规律进行追问的内涵。因此,可解释是计算教育学的应有之义,可计算与可解释是计算教育学发展的两大目标。
计算教育学的研究范式转型方兴未艾,在人工智能技术的快速演进和加持下,如何开展教育量化分析与计算建模吸引了更多学者的关注,从教育可计算到教育可解释计算,是一个长期发展的过程。首先,需改变以往研究观念,从勤于技术突破回归到教育的内涵,在围绕核心任务开展研究和实践时注重理论分析和意义阐释,运用可解释方法揭示隐藏在数据背后的内在关系与运行逻辑,以及教育发展演变的客观规律。以可解释计算技术为用,将技术落实于服务教育本身,有助于揭示教育现象或问题的本质,突破教育教学规律挖掘的研究瓶颈,加快计算教育学研究范式的转型进程。
(二)技术突破: 破解算法黑箱难题
作为掀起过去十年人工智能发展热潮的三大核心驱动力之一,深度神经网络通过大规模神经元连接、可迭代优化的算法训练机制进行数据驱动的分析归纳与精准决策,广泛应用于在线学习、智慧教室、智能评测、教育管理等场景,促进了智能教育创新发展。但深度神经网络算法所涉及的复杂技术和专业知识、蕴含的繁杂数据和设计结构,对多数人而言仍是一个黑箱,难以理解模型的工作机理与决策依据,存在模糊性和难解释等问题。因此,在人工智能与教育加速融合的当下,一方面需避免因盲目追求模型高性能而陷入“技术乐观”的漩涡,另一方面要结合教育场景和主体需求,发展具有高可解释性、强泛化能力的智能教育技术,才能触及寻求教育知识和表达教育规律的本质。
事实上,如何破解深度神经网络算法黑箱难题,建立兼具稳定性和鲁棒性的可解释计算模型,已引起智能教育等多个领域学者们的广泛关注,发展出不同的可解释技术范式。例如对于特定的深度神经网络模型,通过可视化模型内部神经元的行为来理解算法的工作机制,或者针对特定任务,利用知识图谱来增强神经网络模型的语义推理能力,达到可解释目的。其中,因果推断技术与深度神经网络的结合,成为当前研究前沿,能够给出更加稳定与可靠的解释。通过引入因果机制,有助于建立多方法、多通道和多维度视角下有意义变量之间的深层关联,从数据层面客观与准确把握教育研究中的因果机理。
(三)应用创新: 推动教育人机共融
人工智能的技术进步及应用推广带来人机交互革命,尤其是以ChatGPT为代表的最新技术,使人与机器之间的交互变得更加自然和丰富。对智能教育而言,如何充分发挥人与机器智能的各自优势,开展“师-机-生”多模式协同交互应用创新,推动教育人机和谐共融,成为智能时代教育与技术融合的方向。近年来,虽然智能教育快速发展且新应用不断涌现,但由于智能技术加持的核心业务逻辑普遍缺乏透明度和可解释性,人机互信机制薄弱,教育人机共融还处于起步阶段。比如,利用互联网开放大数据训练而成的算法模型可能会把偏见、不良价值观等内容带入教育场景,引发智能教育场域下的信任危机。基于智能算法的学习者画像模型通常对学习者不透明,学习者无法理解画像如何生成及演化,难以利用画像蕴含的丰富信息开展自我反思以及进一步提升其自我效能感和学习投入度。
智能教育系统的透明化与可信化,是促进教育人机共融的前提。首先,需探究机器与人类混合形成的社会规律,以更好地理解人工智能的行为及其对人类的影响,最大程度发挥人工智能的潜力并管控风险。其次,需建立以保护学习者隐私为核心的数据使用规范,利用差分隐私、联邦学习等数据加密、共享技术来实现更为可靠的教育数据使用机制。此外,结合不同智能教育场景,发展具有高可解释的应用技术与服务,提升教育人机互信与共融能力。比如,对于个性化学习系统,通过构建开放式学习者模型,使学习者明晰模型的决策过程及自我成长规律,并支持学习者与模型协商来更新模型,实现人机之间高度互信与协同进化,有效促进学习者自我反思与学习投入。
二、教育可解释计算的逻辑框架
结合以上分析,按照智能计算模型的一般流程,本研究提出教育可解释计算的四阶段逻辑框架,如图1所示。该框架分为需求分析、数据处理、模型构建与评估反馈四个阶段,可作为智能教育不同场景下开展可解释计算任务设计和开发的一般性参考框架。
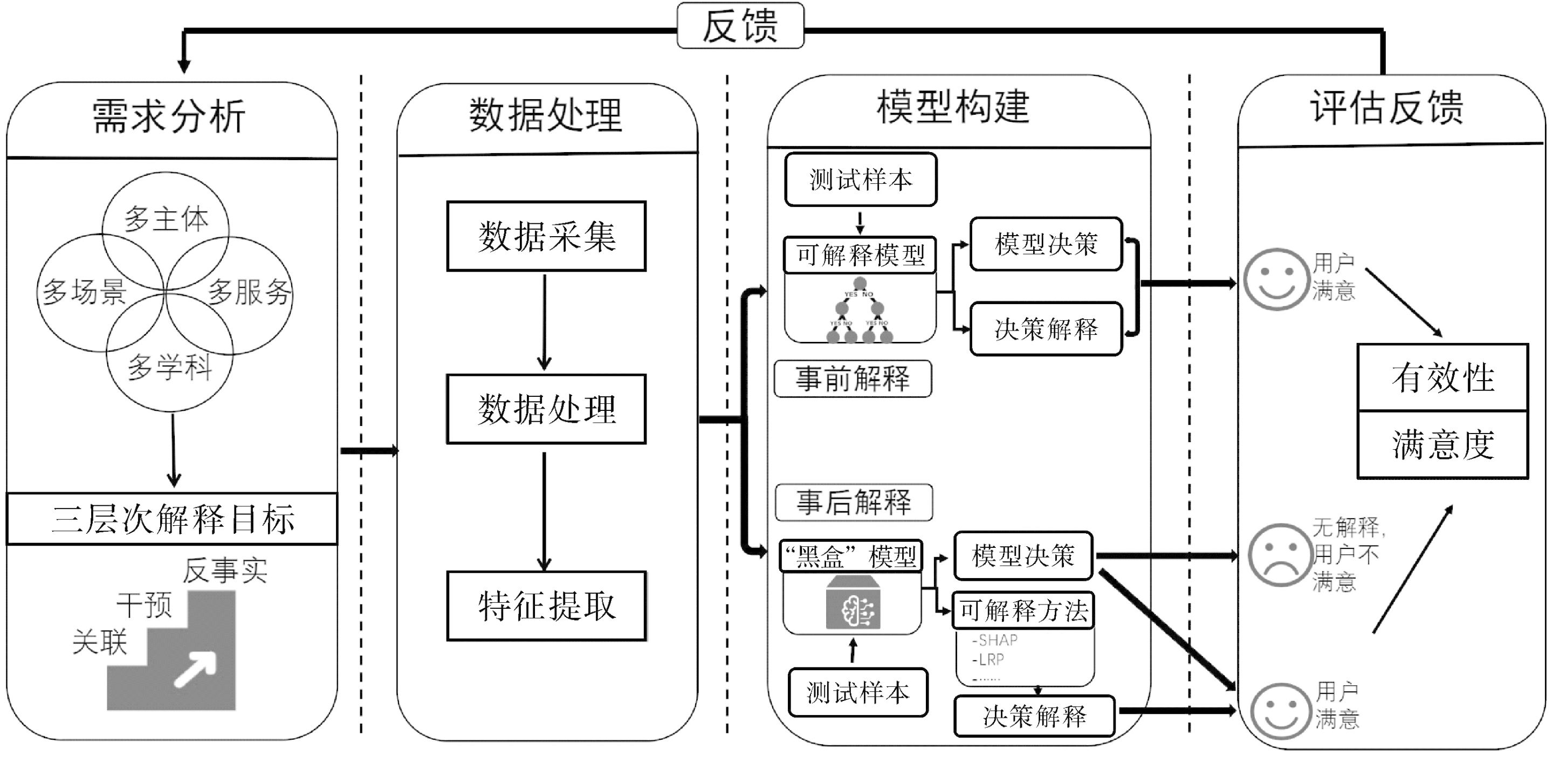
图1 教育可解释计算逻辑框架
(一)需求分析
教育是一个复杂系统,具有多主体、多场景、多服务、多学科等特征。不同主体的可解释诉求不尽相同,如学生更希望得到在特定学习任务上的表现评判及自我指导提示,教师则更侧重于获得关于教学设计或方法有效性的反馈,以进行针对性调整。此外,对于可解释需求分析,还需结合线上线下、课内课外、虚拟现实等不同场景,教育测评、智能辅导、自适应学习、课堂评价、智能治理等不同应用服务,以及语言类、逻辑类、艺术类等不同学科的特点,以提供符合教育规律、满足主体需求的解释。
针对教育可解释需求的复杂多样性,受珀尔“因果关系之梯”思想启发[3],提出教育可解释计算三层目标。第一层为观察“关联”,旨在从数据中挖掘出感兴趣变量之间的相关性,如学习行为特征和学习成效之间的关系,以检验学习成效预测模型的合理性,或帮助教师或学生去发现影响学习成效的潜在因素及其关系,并利用这些信息去改进预测模型或提升成效。第二层为“做出干预”,旨在检测并纠正数据集产生的偏差和影响决策结果的无关特征,进一步提升智能计算模型的性能,或者探寻算法模型内部的因果机制,对模型决策的解释以及所反映的输入和输出之间的因果关系将增加利益相关者对机器的信心,建立教育主体对机器决策的信任。第三层为“反事实推理”,旨在利用反事实思维弥补随机实验难以解决的伦理问题,可用于解释和演示将模型预测更改为预定义输出特征值的最小变化,回答个性化学习应用中诸如“假设学习者换一种学习路径,学习成效会不会提高”之类的问题。
(二)数据处理
明确了可解释需求与任务,下一步是数据采集、处理和分析。在多数智能教育场景下,除了采集与学生表现直接相关的结果性数据以外,更重要的是获得可能影响学习表现的多维过程性数据或情境类信息,例如各种学习行为、学习风格、学习场景等,确保后续对有意义特征的提取和解释,同时也为下一步构建更精准的计算模型奠定数据基础。数据是构建智能教育系统的关键基础设施,其质量和容量会显著影响模型的决策,并在很大程度上决定了系统的性能、公平性和安全性。有研究者提出由于低估了数据质量而引发的“数据级联”现象可能广泛存在于各类应用场景中,其带来的挑战包括由于数据问题导致模型错误预测而引起用户信任度下降[4],从而难以在人机之间建立可解释机制。
对于多维教育数据的采集与处理,诸如学习风格可使用软件建模问卷,将学生回答保存在数据库中进行评估。对学习背景数据进行采集时应注意隐私,签订协议保障数据安全。其次,采集多模态数据有利于提取多维特征,使不同通道数据相互印证,能够增强计算模型结果的可信度。此外,在教育可解释任务中,通过干预原始数据的相应变量进行反事实数据建模,能够增加数据容量,学习到最小的反事实集合作为解释,可避免数据驱动中存在的解释噪音问题并改善数据稀疏问题。从长远来看,针对教育领域特点,通过开发标准化的指标衡量数据质量,建立创新激励机制以认可数据工作,并开放数据库解决数据不平等举措,能够有效改善“数据级联”问题,支撑高质量可解释计算。
(三)模型构建
模型构建是教育可解释计算的核心,包括算法模型的构建及相应的可解释技术。在智能教育领域,深度神经网络以其强大的数据拟合能力成为建模算法的主要选择,但也因其黑箱属性,国内外学者研发了大量的可解释技术,帮助用户理解模型的工作过程和决策机制。根据模型本身是否可解释,现有的可解释技术可分为事前解释和事后解释两大类。
对于事前解释技术,一类是在模型构建过程中加入可解释组件来解释算法的运行逻辑,包括具有特殊功能的插入层、专门设计的神经元以及模块化的体系结构等,比如使用注意力权重[5],可用于解释不同输入特征如何影响模型的决策结果或提供特征间关系的局部解释。另一类是采用正则化技术,将模型的训练优化引向更具解释性的方向,包括可分解性、稀疏性和单调性等正则化方向。比如对于单调性约束方法[6],期望得到当指定输入特征值增加或减少时,模型预测输出值相应增加或减少的信息,以此解释模型输入特征与输出结果之间的关系。事前解释技术由于与特定模型结构深度耦合,难以用于解释其他模型,并且通常会在模型性能与可解释性之间进行取舍,具有一定的局限性。
相比事前解释,事后解释技术可用于解释不同的模型,且不用考虑为了追求高可解释性而牺牲模型性能。相关技术包括显著性表征类方法,如计算合作博弈shapley值[7],对输入单元的重要性进行量化和分析,进而探索模型输入特征与输出结果之间的关系,例如应用于学习分析场景,可表示多个学习行为特征在决策学习者“优良中差”等级时的重要性;层级相关性传播方法,通过将相关性从模型的输出层反向传播到输入层来解释模型的内部决策机制;构造代理模型解释类方法,如使用知识蒸馏方法,利用白盒模型提炼出黑盒模型中学到的知识以解释其决策机理,在教育场景中常使用决策树作为白盒模型,利用决策树内部的规则类知识为教师提供可解释信息来洞察和帮助学习者;反事实类解释方法,可提供形式如“是X引起了Y吗”“假如X没有发生会如何”的因果类解释信息,用于解释将预测结果更改为预定义输出时特征值的最小变化或观察输入反事实数据对预测结果产生的影响。以学习归因分析为例,有研究者将反事实方法用于分析考试预测模型[8],可得到学生若要顺利通过期末考试,需重点关注或改变哪些输入特征对应的学习行为,能够为学生、教师或教育管理者提供有价值且可操作的建议。
(四)评估反馈
教育可解释计算从需求分析出发,通过数据处理、模型构建等环节,最终还需评估是否满足学生、教师、管理者等教育系统利益相关者的需求,包括解释方法有效性和用户满意度两方面,以此形成反馈闭环,不断评估和优化可解释计算流程,实现“以人为本、人在回路”的教育可解释计算。
对于解释方法的有效性,通常好的方法加入解释组件后模型的性能无明显降低且所使用的可解释性评估指标有所提升,一般从解释精确性、一致性、完整性、普遍性和实用性五个方面进行评估[9]。对于用户满意度,主要采用问卷调查或构建用户满意度心理评估模型。例如美国佛罗里达人类和机器认知研究所的团队旨在开发和评估心理上合理的解释模型,基于如何理解用户心理需求并有效加以解释的问题,提出了可解释人工智能对使用者心理和行为所产生的影响及形成的评估框架,有助于用户建立人工智能系统的心理模型,同时可以从准确性和理解力方面评估可解释性。目前,教育系统中的可解释评估反馈主要通过在线调查或师生访谈等方式,缺乏专门针对教育可解释计算的用户满意度心理评估模型。
三、教育可解释计算的技术路向
面向智能教育的可解释计算研究已受到学术界的广泛关注,尤其是在可解释技术上进行了各种创新探索。以智能教育领域的研究热点“知识追踪”为例,近年来已有部分研究突破传统仅关注模型性能的局限,开始发展可解释的知识追踪模型,以提升模型的可解释能力,释放更大的教育价值。知识追踪是一种数据驱动的学习者建模技术,旨在利用历史学习行为数据,建立动态追踪模型,自动评估学习者在不同时刻的知识掌握程度,并预测其未来学习表现,是实现精准化教、个性化学的核心技术。按照教育可解释计算的三层目标,剖析知识追踪可解释技术的最新进展,以此窥探智能教育可解释技术的发展态势。
(一)观察“关联”
观察“关联”是“因果之梯”的第一层,当前知识追踪可解释技术研究大多位于这一层。该类方法侧重于分析知识追踪模型的输入数据,通过计算模型输入特征对决策结果的贡献来提供解释。
首先是知识追踪事前解释技术,可分为两类。第一类是在模型构建或预测过程中引入有教育意义的参数或因素,比如Deep-IRT模型利用认知诊断理论,分别对学生能力和题目难度建模,显式表征与模型预测结果相关的参数,再将建模后得到的能力和题目难度参数值带入模型输出层,以提高模型的可解释性;ABKT模型将学习者的能力因素引入认知状态建模和学习反馈归因过程,使模型能够从知识和能力两个角度分析学习过程,同时提升了模型的数据拟合能力与解释性。第二类是在知识追踪模型中加入可解释组件,比如基于注意力机制的关联解释,利用注意力权重信息来解释不同特征之间关联程度的大小。基于注意力的可解释知识追踪模型包括 EKT、SAKT、RKT和AKT等,其共同点都是通过计算学生当前答题记录和历史记录之间的相关性,进而解释模型在预测时重点关注的是哪些记录。HeTROPY模型通过引入具有最大熵正则化器的异质性机制来生成注意力分布,在预测过程中鼓励模型关注学习序列中异质和相近的知识点,最大注意力熵也有助于模型获得知识点之间的多跳关系,通过追溯学生历史学习序列中的相关知识点,为模型预测学习表现提供解释依据。其次,关于知识追踪的事后解释技术,典型工作是使用层级相关性传播方法,利用神经网络的反向传播机制,将知识追踪模型输出层的预测信息通过中间层的神经元及其连接逐层传回输入层,然后计算每一个输入与最后预测结果的相关性来提供解释。
(二)进行“干预”
相对于第一层侧重于对数据进行观察与分析来揭示感兴趣变量之间的关联关系,第二层则更进一步,可通过操纵数据对输入变量进行干预,根据结果变量的变化来揭示变量之间的因果关系,对于解释或优化知识追踪模型都具有十分重要的价值。
有学者基于深度知识追踪模型提出一种新的因果门控循环单元模块[10],用一个可学习的排列矩阵表示知识点之间的因果顺序,以及一个低三角矩阵表示知识点之间的因果结构,从而实现端到端学习知识点之间的因果关系,以提供基于知识点的因果解释和推理任务,如评估特定教学干预的效果。此外,在构建具有自解释能力的知识追踪模型时,可利用干预变量的方法纠正数据集中一些无关特征所带来的偏差,缓解因偏差导致的决策错误而引发的算法不公平问题,在保持模型具有高可解释性的同时进一步提升其预测精度。对于知识追踪的事后解释技术,则可通过干预输入的学习行为特征数据,按照“如果实施X行动,那么Y会怎样”“怎样让Y发生”的逻辑来揭示变量之间的因果关系,以解释对学习表现预测结果具有最大因果效应的学习行为特征。本团队近期的研究结果表明[11],通过干预知识追踪输入序列中的变量计算个体因果效应值,然后利用遗传算法进行筛选优化,找出对模型预测贡献最大的解释子序列,可实现对学生答题正误情况的归因分析与错因追溯,同时得到知识点因果关系图,并提出相应的评估指标检验了解释方法的有效性。
(三)“反事实推理”
在反事实世界,通过对数据进行相应的干预实验能够得到在真实世界无法观察的规律。目前,基于反事实推理的知识追踪可解释研究相对较少。
知识追踪模型可根据想象进行反事实推理,通过干预实验观察模型输入的学习行为特征和预测输出的学习表现之间的因果关系,可以回答诸如“假设学生换一种做题顺序是否就不会做错某道题目”之类的问题,利用反事实思维推测影响学生答题表现的因素。有学者使用反事实方法创建模型输入实例训练知识追踪模型参数进行预测[12],推断学生想要达到满意学习表现需付出的最小努力条件。此外,也有学者运用对比解释法进行事后解释[13],计算与知识追踪模型预测结果相关的输入特征重要性,以及使用多样化反事实解释法生成反事实实例来解释模型预测,推断导致不同预测结果的初始实例的最小可能变化。反事实推理提供了一种开放且灵活的方式去探索影响学生学习表现的可能因素,不仅有助于挖掘智能教育场景下有意义变量之间的因果关系,揭示学习规律,解释学习现象,而且能够为知识追踪的下游应用,比如学习路径规划、学习资源推荐等智能教育系统的各种功能,提供策略支持和决策依据,支撑学生以更适配的知识路径、更高效的习题顺序开展个性化学习。
四、未来展望
(一)注重理论引导
理论与数据双驱动已成为当前人工智能发展的新趋势,不仅有利于增强算法模型的性能,而且能够在理论的引导下提升模型的可解释性。智能教育是一个涉及教育学、信息科学、认知科学等多学科交叉的领域,如何利用这些学科丰富的理论作为先验知识来构建智能教育计算模型,提升其可解释能力与质量,是值得进一步探究的问题。如融合人类遗忘机制、项目反应等认知科学理论的深度知识追踪模型,能够赋予模型有意义的结构或参数,显著提升模型的可解释能力,并且使解释变量及过程具有可靠的理论依据。
(二)完善评估体系
建立面向智能教育领域的统一、易测的可解释性评估标准和规范,对发展教育可解释计算至关重要。未来,一是需突破当前以精准性、一致性、完整性、普遍性和实用性等定性化评估为主的范式,结合具体教育场景和可解释任务提出一套量化评测指标,使不同的可解释模型之间易于公平对比,推动教育可解释技术快速发展;二是需进一步强化可解释性评估的主体性,以是否满足人的心理需求为出发点,建立面向教育人机协同交互的心理模型与满意度评测指标,发展“人在回路”的教育可解释技术评估框架。
(三)关切个性需求
促进个性化学习是智能教育的一大目标,通过感知和理解学习主体的个性化需求,提供适应性服务。随着人工智能技术的快速迭代及人机协同关系的不断深化,人与机器之间的互释和互信变得愈发重要。例如开放式学习者模型,本质上是通过人机协商,建立学习者与算法模型的双向感知和理解机制,并由此带来学习投入与成效的提升。因此,在教育可解释建模过程中,关切学习主体个性化需求,融入个性化因素,有助于增进人机和谐共融与协同进化,实现教育从可解释计算到个性化可解释计算的跃升。
参考文献
[1]Gunning D,Aha D.DARPA’s explainable artificial intelligence (XAI) program[J].AI Magazine,2019,40(2).
[2]刘三女牙,周子荷,李卿.再论“计算教育学”:人工智能何以改变教育研究[J].教育研究,2022,43(4).
[3][美]朱迪亚·珀尔,达纳·麦肯齐.为什么[M].江生,于华,译.北京:中信出版集团,2019.
[4]Sambasivan N,Kapania S,Highfill H,et al.“Everyone wants to do the model work,not the data work”:data cascades in high-stakes AI[C]//Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems.New York:ACM,2021.
[5]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.Cambridge:MIT Press,2017.
[6]You S,Ding D,Canini K,et al.Deep lattice networks and partial monotonic functions[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.Cambridge:MIT Press,2017.
[7]Ancona M,Oztireli C,Gross M.Explaining deep neural networks with a polynomial time algorithm for shapley value approximation[C]//Proceedings of the 36th International Conference on Machine Learning.New York:ACM,2019.
[8]Tsiakmaki M,Ragos O.A case study of interpretable counterfactual explanations for the task of predicting student academic performance[C]//2021 25th International Conference on Circuits,Systems,Communications and Computers.Piscataway,NJ:IEEE,2021.
[9]Fan F L,Xiong J,Li M,et al.On interpretability of artificial neural networks:a survey[J].IEEE Transactions on Radiation and Plasma Medical Sciences,2021,5(6).
[10]Kumar N A,Feng W,Lee J,et al.A conceptual model for end-to-end causal discovery in knowledge tracing [C]// Proceedings of 16th International Conference on Educational Data Mining.Worcester,MA:IEDMS,2023.
[11]Li Q,Yuan X,Liu S,et al.A genetic causal explainer for deep knowledge tracing[J].IEEE Transactions on Evolutionary Computation,2023.
[12]González-Brenes J P,Huang Y.“Your model is predictive—but is it useful?” theoretical and empirical considerations of a new paradigm for adaptive tutoring evaluation[C]//Proceedings of the 8th International Conference on Educational Data Mining.Worcester,MA:IEDMS,2015.
[13]Swamy V,Radmehr B,Krco N,et al.Evaluating the explainers:black-box explainable machine learning for student success prediction in MOOCs[C]//Proceedings of the 15th International Conference on Educational Data Mining.Worcester,MA:IEDMS,2022.