继今年5月在多步推理阅读理解评测HotpotQA夺冠后,哈工大讯飞联合实验室在认知智能及通用自然语言处理技术上再获突破。8月27日,哈工大讯飞联合实验室与河北省讯飞人工智能研究院联合团队以总平均分90.7位列权威自然语言理解评测GLUE榜首。
GLUE评测(General Language Understanding Evaluation)由纽约大学、华盛顿大学和谷歌DeepMind共同举办,旨在评测模型在通用自然语言理解任务上的效果。GLUE评测举办以来吸引了众多知名研究机构和高校参加,其中包括谷歌、微软、Facebook、阿里巴巴达摩院、平安科技、百度、华为、斯坦福大学等。
>GLUE评测
GLUE评测包括三大任务类别,共计10项任务,其中包括9项主任务和1项诊断任务(不计入总成绩)。其中9项主任务分别为:
单句任务:CoLA(语法检测)、SST-2(情感极性判断)
相似度及复述任务:MRPC(语义等价性)、STS-B(相似度检测)、QQP(问句语义等价性)
推断任务:MNLI(文本蕴含)、QNLI(问句文本蕴含)、RTE(文本蕴含)、WNLI(Winograd Schema Challenge)
与以往自然语言理解类评测不同的是,GLUE评测更加侧重于全面评测模型在不同自然语言理解任务上的综合表现,而非单一任务上表现。业界知名的预训练语言模型,例如谷歌提出的BERT、Facebook提出的RoBERTa、斯坦福大学提出的ELECTRA等均在该评测当中,因此GLUE也是目前关注度最高的自然语言理解评测之一。
GLUE评测要求参赛系统根据测试集输入文本给出相应预测,并将预测结果上传至打分服务器,最终结果是九项主任务得分的平均值。由于最终排名取决于总平均分,这使得模型仅在个别任务上获得提升并不能够带来总分上的明显提升,模型需要在大多数任务上取得提升才能够从众多顶尖评测队伍中脱颖而出。
>夺冠系统
本次哈工大讯飞联合实验室提交的MacALBERT + DKM模型以总成绩90.7分位居GLUE评测榜首,其中MRPC、QNLI、WNLI任务达到或超过榜单最好水平。除了9项主任务之外,GLUE评测还设立了一项诊断任务(AX),用于检测模型在不同语言学问题上的表现。本次提交的模型在诊断任务中也取得了52.6分的好成绩。
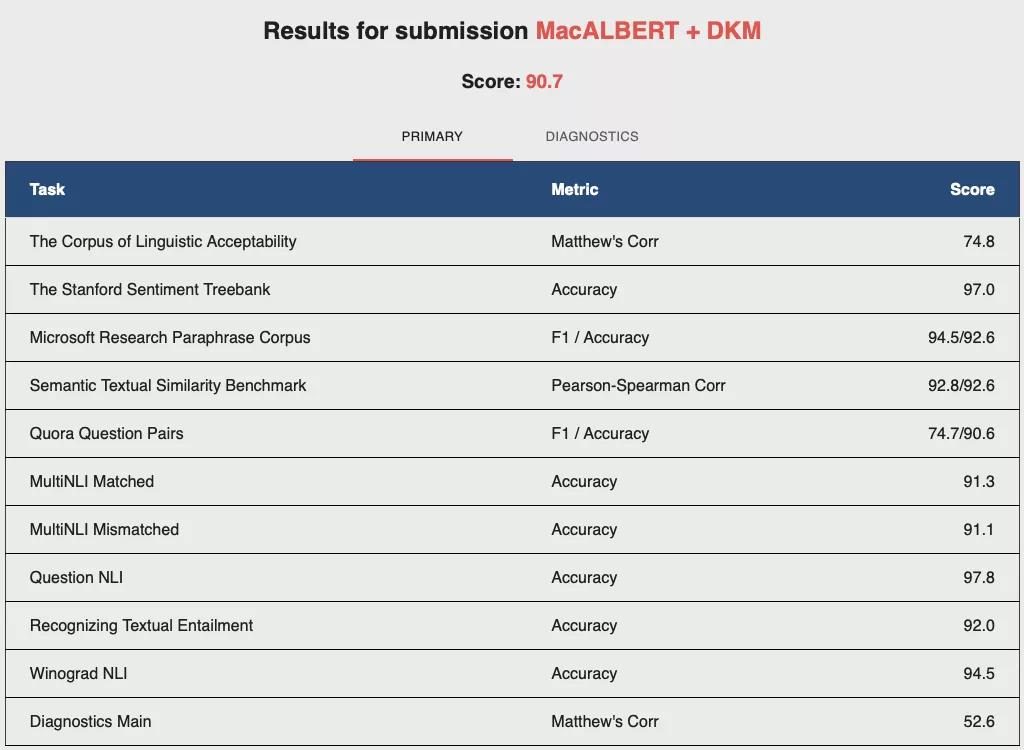
GLUE夺冠模型MacALBERT + DKM详细成绩
本次夺冠的模型MacALBERT + DKM,在业界领先的预训练语言模型ALBERT基础上加入了自主研发的语义纠错型掩码语言模型(MLMascorrection),进一步提升了模型在相似文本上的区分能力。另外,我们创新地提出了动态关键词匹配技术(DynamicKeywordMatching),可以从输入文本中动态抽取出关键部分并辅助预训练模型做进一步决策。例如在情感分类任务中,该算法能够通过语义计算出与情感极性相关的语义分量;在语义等价性任务中能够抽取出两个句子中语义不同的部分。
>中文预训练模型
哈工大讯飞联合实验室不仅在国际比赛中屡获佳绩,也持续关注和积极推动中文信息处理技术的研究与发展。近些年来,预训练语言模型(Pre-Trained Language Model)技术不断发展极大地推动了自然语言处理领域的进步。哈工大讯飞联合实验室第一时间将业界最新技术结合自身技术研究及资源优势,率先并持续推出多种中文预训练模型,在多个自然语言处理任务中获得显著效果提升,目前已成为最受欢迎的中文预训练模型资源之一,GitHub总星标数超过5000。同时,针对预训练模型体积庞大、难以满足产品上线需求等问题,今年3月推出自然语言处理领域的知识蒸馏工具包TextBrewer,提供了一种方便易用的模型压缩手段。未来,哈工大讯飞联合实验室将继续扎根于中文信息处理,提供效果更好、更加易用的自然语言处理技术和资源。
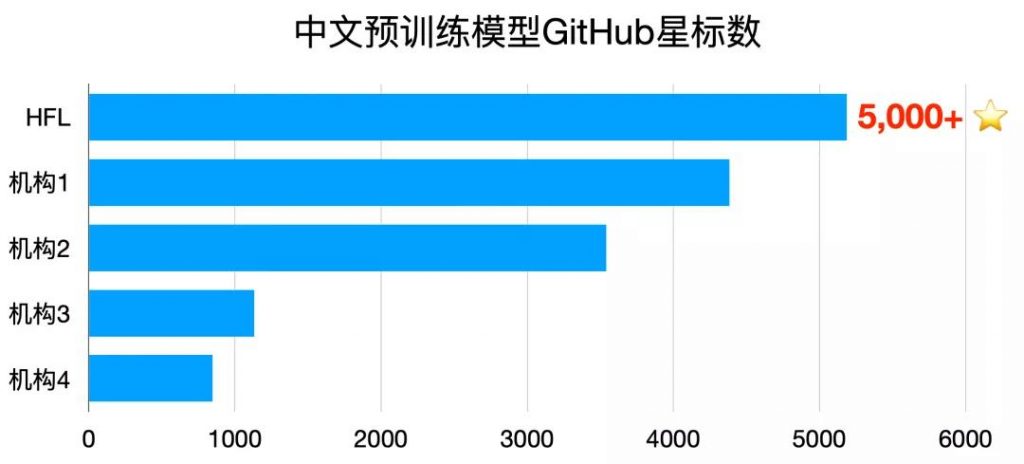
中文预训练模型GitHub星标数(截至2020年8月27日)
>应用落地
预训练语言模型技术已成为自然语言处理领域中不可或缺的底层技术,认知智能通用技术的提升带来多场景认知智能任务及应用水平的提升。2019年12月,哈工大讯飞联合实验室隆重推出飞鹰智能文本校对系统,提供了拼写纠错、语法纠错、标点纠错及敏感词检测等功能。飞鹰校对推出以来底层技术和功能不断更新。飞鹰校对最新搭载了由哈工大讯飞联合实验室自主研发的中文预训练模型,预训练数据规模达到了100G以上,有效提升了文本校对的效果。

飞鹰智能文本校对网页版界面
目前飞鹰校对已应用在讯飞教育作文智能批改、司法文书自动质检等多个领域的文本校对项目中,同时已与多家出版行业机构签约使用,并向个人用户提供免费在线服务。未来飞鹰校对将针对不同领域的校对需求逐步开放更多领域的校对服务,并解锁更多个性化文本校对技能,持续提升文本校对的使用体验。
来源:长三角信息智能创新研究院 编辑:唐菁莲 校对:罗添 初审:施羽晗 终审:聂竹明